聊聊 MySQL 索引与索引设计
本文讲的都是比较基础的点,原理点到为止,适合人群为数据库小白,希望能够从数据库层面进行一些优化的同学。
最近在做旧项目改造的时候发现了很多不合理的索引设计,或者干脆就没有设计索引,开发者仿佛把在线业务的表当做了离线表那样想怎么查就怎么查,导致了整个接口相当缓慢,甚至有可能拖垮整个服务 / DB。
于是我发现一些很常规的优化似乎其实并不是每个人都很清楚,所以今天就来聊聊 SQL 的索引优化。
因为我们的项目都是 MySQL / MongoDB 的,而我基本也只学了 MySQL,因此这里以 MySQL 为主,MongoDB 为辅来进行索引设计的解读。
开始之前:数据构建
如果你只想看看理论经验,也可以跳过这个步骤
在正式开始之前,先让我们构造一下之后要作为例子的数据(不然讲起来又枯燥又抽象)。
假定我们有这样一张博客文章表,用来存储用户的文章数据:
CREEATE DATABASE test;
USE test;
CREATE TABLE IF NOT EXISTS blog_posts (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content LONGTEXT NOT NULL, -- Use LONGTEXT to store large data
author VARCHAR(100) NOT NULL,
created DATETIME NOT NULL
);然后我们需要基于这个构造数据集,这一步直接找 GPT 写就行了,大致诉求如下:
- 构造十万条数据
- 其中有十个 author,其中包括了一个叫 skyao 的(因为之后要举例子),content 的大小在 0-1MB 不等
因为之后我们将通过 id / author 和 created 来进行排序检索和数据获取,因此这些是必须的。
没有索引的情况下会发生什么
我们以实际场景为例,在博客首页中,我需要展示我自己的文章,并按照时间倒序排列。
因此我们要执行的语句是:
SELECT id, title, content FROM test.blog_posts WHERE author="skyao" ORDER BY created DESC LIMIT 10 OFFSET 10 # 假设我们翻了个页假设我们什么索引都不加,那么查询这 10 行数据在我的电脑中需要 1 分多钟。
如果我们 EXPLAIN 会发现,这其实是个全表查询,也就是说他要扫描全表才能得出最终的结果,实际开销(Cost)也是相当的大:

考虑到这篇文章的受众,因此解释一下 EXPLAIN 语句可以查看 SQL 的执行计划,来确定是否如你预期的那样。在 SELECT 语句前加 Explain 就可以了,因为本文也会稍微提及 MongoDB,因此之后会再说下 Mongo 的 Explain。此时如果我们加上了索引 created,你就会发现,开销少了很多:

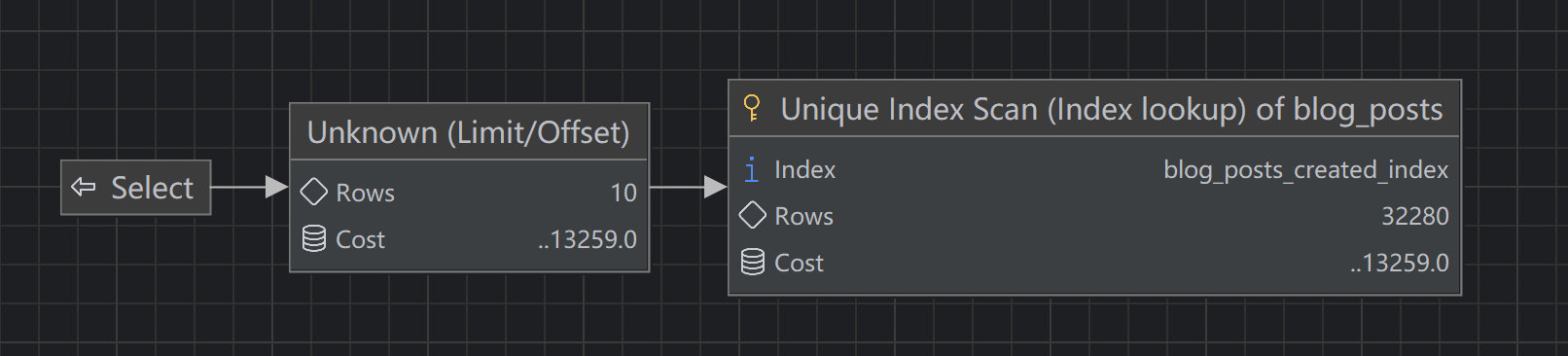
而如果我们用的是 author和created的联合索引,我们会发现效率竟然变慢了:
但如果我们将语句换成了游标性质的,或者是归档最近 X 天的文章,那么可能两种索引的效果又不一样了,比如:
SELECT id, title, content FROM test.blog_posts WHERE author="admin" AND id >= 50 ORDER BY created DESC LIMIT 10;
SELECT id, title, content FROM test.blog_posts WHERE author="admin" AND created >= "2024-08-26 12:55:30" ORDER BY created DESC LIMIT 10;author + created:

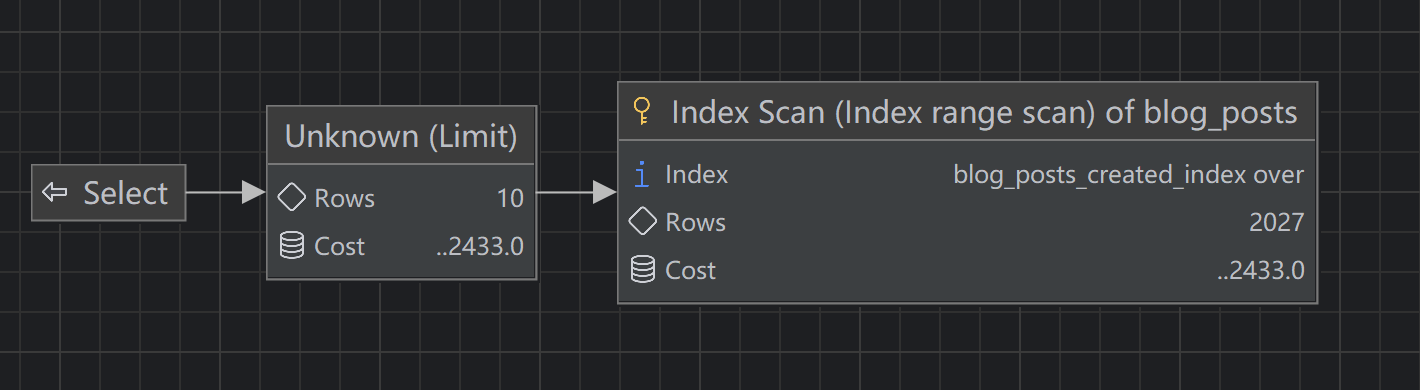
created:
之所以 created 排序会差这么多,是因为 author + created 的查询 Explain 的 Extra 中写的:Using index condition; Backward index scan;而单 created 还得需要 where 去检索表。
从中我们可以看出,加索引总比没加好,但是索引也并不是一个万精油,在不同的查询条件下,不同的索引会产生不同的效果。
索引拉满会发生什么
在上面的例子中,按月归档、游标分页和页码分页都是非常常见的需求,但是有效索引却是截然不同的,聪明的读者可能已经想着「小孩才做选择、大人全都要」。
但是索引并不是全然没有代价,在这里我们简单介绍下索引的原理。
首先我们知道,InnoDB 使用的是 B+树,先不讲 B+树这个数据结构相比 B 树的优点之类八股的问题,总之它是一棵树。而每个建立的索引树本质上都是一种空间换时间的做法,下面用一张高性能 MySQL 的图来介绍节点的搜索。
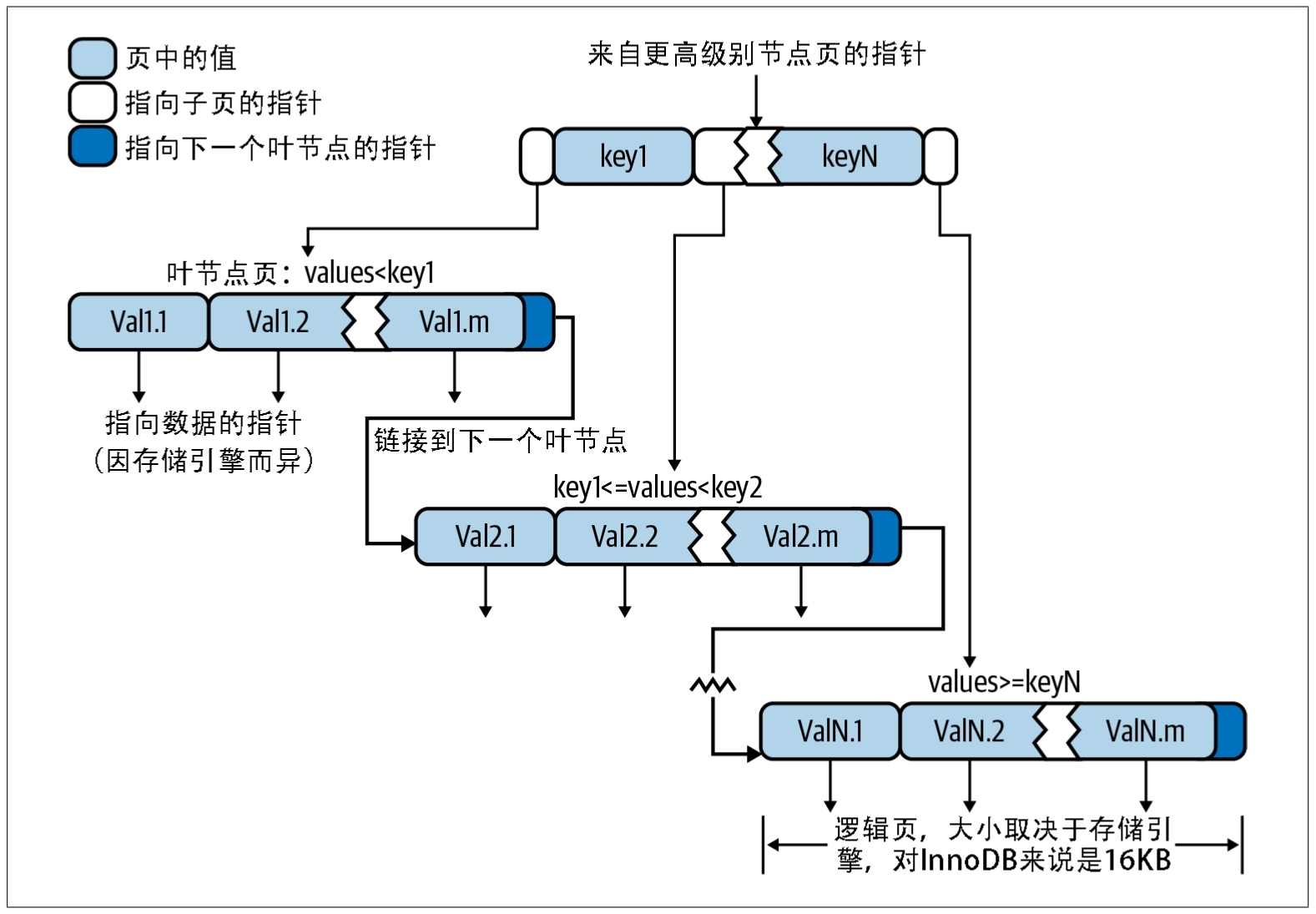
简单的来说,建立索引的过程其实就是在建立逻辑页,而每一个数据页都要 16k,每个索引都有自己的开销,那么磁盘空间占用就变大了。
另一方面,新增数据相当于需要在一个个树中插入值,这也是有一定开销的,比如:
- 新增记录就需要往页中插入数据,现有的页满了就需要新创建一个页,把现有页的部分数据移过去,这就是页分裂
- 若删除了许多数据使得页很空闲,就需要页合并
页分裂和合并,都会有I/O代价,且过程中可能产生死锁。
以我们建了一个索引的表为例,可以用下面的 SQL 查看数据量:
mysql> SELECT DATA_LENGTH, INDEX_LENGTH FROM information_schema.TABLES WHERE TABLE_NAME='blog_posts';
+-------------+--------------+
| DATA_LENGTH | INDEX_LENGTH |
+-------------+--------------+
| 54863085568 | 2637824 |
+-------------+--------------+因此,如果你一直在无脑建立索引,那么带来的代价就是磁盘的无限消耗和写入速度的降低。
当然,如果你说:我不 care 写入、也不心疼磁盘;即使如此,你如果建的全是单列索引(比如一个 created 和 一个 author),他也并不会有效利用两个索引(毕竟这是两棵树),而是会选其中一个效果更好的。
这里补充一点:尽管 MySQL 引入了 index merge 但是也会带来额外的开销,对此《高性能 MySQL》是这么总结的。
- 当优化器需要对多个索引做相交(相交操作是使用“索引合并”的一种情况,另一种是做联合操作)操作时(通常有多个AND条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。
- 当优化器需要对多个索引做联合操作时(通常有多个OR条件),通常需要在算法的缓存、排序和合并操作上耗费大量CPU和内存资源,尤其是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。
- 更重要的是,优化器不会把这些操作计算到“查询成本”(cost)中,优化器只关心随机页面读取。这会使得查询的成本被“低估”,导致该执行计划还不如直接进行全表扫描。这样做不但会消耗更多的CPU和内存资源,还可能会影响并发的查询,但如果单独运行这样的查询则往往会忽略对并发性的影响。通常来说,使用UNION改写查询,往往是最好的办法。
简单的来说,不要太指望和依赖 MySQL 的自动优化(包括 Buffer Pool / Cache 这类会让你产生错觉,以为自己的查询还可以),更重要的依旧是自己设计好索引。
如何正确的设计索引
在前面我们已经展示了不同索引即使命中了,他的扫描行也存在着差距;但是建立大量索引又会造成可预期的副作用。
对于有 Where 就有索引的行为,我们可以考虑查询语句本身是否能够收敛到索引行,而不是为查询语句去建立索引。对于一些查询,我们甚至可以引入外援,比如我要对正文和标题进行搜索,用 ES 肯定比 LIKE 更为有效。而如果没有这些外援,就不应该将 content 纳入查询条件中。
其次,我们要知道索引 created+author和索引 author+created是不同的。但是有了 author+created,那么我们不需要再建立 author 的单列索引。因为我们前面介绍了树的构建,因此这一部分应该很好理解。
那么我们如何考虑我们到底应该建 created+author还是author+created呢?
在上面的例子中,created (+ author) 的效果会比 author + created 好很多,有一半是因为我们的 author 并不太具有选择性,在十万行数据中,我只安排了五个作者(而在实际场景下本人的博客只有一个作者),此时 author 几乎是无效的,因为 author 并不能减少数据规模。
但是让我们设想一个实际的视频平台,此时一个平台可能有几百万个用户,大部分用户的投稿数可能不超过十个,而从中先筛选用户,再筛选时间,就一定会比先筛选时间,再筛选用户要高效的多。
而站在业务的角度,我们可能会有很多基于用户的操作,比如控制展示权限、个人首页等等,author 在前的组合索引可以有大量的应用场景。
也就是说,对于组合索引来说两个比较常规的原则是:
- 尽可能可复用的列作为前缀
- 选择性强的列作为前缀
当然,尽管不同索引 cost 可能会相差一些数量级,但在实际执行上,可能就差了几毫秒,相比全表扫描来其实还是少了不少的。因此不一定要强迫自己以最佳实践命中每一个索引,需要一定的取舍:
比如,假设一个用户的投稿数经过筛选过后只剩下 10 条,此时组合索引中有无 created 并没有多大的差别。
为何有的时候没有命中索引
假设我们建立了 created索引,然后执行下面的语句:
SELECT id, title, content FROM test.blog_posts WHERE author="skyao" ORDER BY created DESC
Explain 后你会发现他依旧是全表扫描,并没有命中索引。
这是因为 MySQL 在查询分析后发现,这玩样儿还不如直接读表快呢。这就涉及到了一个问题:回表。
回表
尽管我们的索引加快了查询过程,但是光一棵索引树并不能拿到我们需要的全量数据,比如在这个语句中,我们需要 title 和 content,而这两条数据在索引树中并不存在,所以需要拿着 id 再去表中查找。
在上面的例子中,无论怎么样都相当于读了一遍全表,因此 MySQL 分析后决定不使用这个索引。
在「回表」这个步骤中隐藏的另一个暗示是:如果我们只需要索引树中的值,那不就不需要回表了吗?性能会更快。
这是正确的,以视频网站为例,我们拿到了某个活动的参与者后,需要显示参与者头像,那么我们先在活动表里筛选出用户,再去用户信息表查询数据。
如果我们的索引是 activity_id, user_id 且我们只需要 user_id,那么此时我们的 SQL 如果是:
SELECT user_id FROM activity WHERE activity_id = 1会比下面的要高效不少:
SELECT * FROM activity WHERE activity_id = 1实际上很多 ORM 都会默认将所有的表字段去除,这在某些情况下会极大的拖累响应速度,包括查询速度和传输速度。
在我们的例子中如果我们不需要 content,那么响应耗时会大大减少。
MongoDB 呢
MongoDB 的 Explain 形如:
db.blog_posts.find({ author: 'skyao' }).sort({ created: -1 }).explain();且因为 MongoDB 是文档数据库,因此在列内也支持更为灵活的索引和不同的索引类型,但由于索引本身还是一棵树,所以在原理上差别并不大。(我也是顺便用的,所以目前没有做很详细的研究)。
总结
在本文中我们主要介绍了索引的一些常识和设计的一些小技巧——
如果你发现命中了索引,但是也没有很快,记得看看是不是索引有用,但不多。
当然,并不是设计好了索引,查询优化就结束了,上面也介绍了一些「SQL 不应该这么写」的部分,导致接口慢这个结果的原因并不是一个索引没加好就完成了的。这一篇写不动了……下一篇再见。
植入部分
如果您觉得文章不错,可以通过赞助支持我。
如果您不希望打赏,也可以通过关闭广告屏蔽插件的形式帮助网站运作。